drupal 大型网站架构建议
服务器架构
高性能网站架构的一个重要因素当然首要的是硬件(如下图)。如果有充足的资源,系统管理员一般喜欢用更多的硬件服务器来解决问题。其实很多服务可以放在一起,开发人员可以选择性的优化或者检查一些数据查询。 不过,当带宽或者用户达到某一个数量,我们就需要解决一些和硬件相关当问题。这就是为什么一个合理的硬件计划是非常重要,可以随意的增减或者筛减硬件,在需要的时候。
一个典型的架构,不管是虚拟机器还是独立机器,通常包含多个服务器,多个数据库,有时还会有多个缓存服务器,所有的这些都需要一个负载均衡服务器来分发请求,这个负载均衡器的配置也变的很关键,比如一台Web或者DB的均衡器配置通常比Cache服务器的均衡器要高。
我们在处理分发处理请求到多个web服务器是非常简洁的做法,但是遇到上传文件处理,就会有问题了。一般我们的负载均衡是基于round-robin算法的,这种情况下,用户在上传操作中提交一个文件到一台web,当用户刷新页面之后,就被分发到另一台web,而这台web上面并没有新上传的文件。为了解决这个问题,我们需要一个文件服务器把几台Web服务器联合一下,通常情况下我们使用NAS(网络附件存储)或NFS(网络文件系统)mount到每一台web服务器上。这样用户上传和处理文件通过NFS就可以共享所有的文件地址了。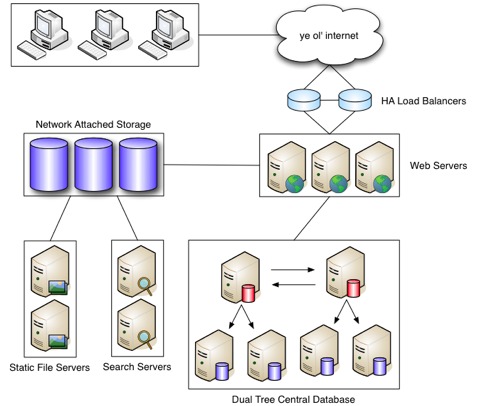
缓存策略
高性能网站构建中另外一个重要的因素,肯定是软件了。为了能以后可扩展、高并发的需求,缓存是一个重要的因素。缓存机制不是相互排斥的,比较优秀的网站都是联合多个缓存。大多数类型的缓存寻求减少所需的磁盘访问量,或者提供给编译成的字节码,使他们更快的运行更接近机器语言更好。
(译者注:将Boost模块应用到极致)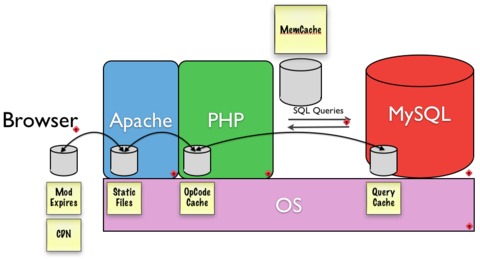
Memcached 是免费、开源并被广泛应用到很多站点的缓存服务器。Memcached经常和MySQL服务器安装在同台服务器上,但由于数据库服务器经常需要很大内存,而Memcached对内存的需求也很大,因此这里就会有内存的瓶颈。在一些情况下,Memcached其实是从数据库服务器上分离出来,运行在独立的服务器上的,这样就避免了和数据库服务器竞争内存的情况。
独立的搜索服务
搜索通常是一个很消耗资源的功能。因此搜索的优化将会对网站的性能带来极大的提升,最好把搜索部分独立处理。Solr是一个开源的易用的搜索服务器,它来自Apache基金会,是Lucene项目的继任者,集成了Lucene的有点,快速的建立索引、搜索,而且它的API是基于HTTP的,如POST、GET操作,并提供较全的文档来供你使用查阅。
在Drupal中,Views模块很像一个可视化的SQL构建和搜索处理工具。在Views 3中,可以把Views的数据源指向到solr服务器上,这样就可以大大的减少数据库的压力和提高查询速度。
(参考 :Drupal北京聚会主题之 – Apache Solr)
优化Apache
在Apache服务器设置中,MaxClients是一个限制并发请求的参数,如果达到了设置的限制,后来的用户就需要等待有请求被处理完成才能继续。但是,如果我们把这个数字设置的很大,这就会有服务器内存用尽的风险。这里有一个标准的公式来计算服务器内存和MaxClients之间的关系:
* 公式: 内存/平均单次请求所需内存 = #Max Clients (最大请求数)
* 举例: 2G(服务器) / 20M (每次) = 100 MaxClients
Apache模块 mod_expires 的设置控制着 HTTP 头的相关信息。如果一个文件被缓存在了用户的电脑上,这个设置可以告诉后续的请求直接用本地的缓存而不要向服务器发送请求,这个设置在Apache上面也很简单,请参考下面的设置。
优化MySQL
MySQL是应用最广泛的数据库之一,也是Drupal上使用最多的数据库,当然Drupal 6也支持Postgres。Drupal 7 有一个面向对象的数据抽象层,以便支持更多的底层数据库。在MySQL的优化中,有几点和性能相关的设置必须心里清楚。
MySQL有一个内建的查询缓存默认是被开启的,因此必须确保更多的查询使用这个缓存,我们需要增加这个设置。比如:
[mysqld] query_cache_size=32M
当网站上线了,经常统计慢查询是一件非常好的习惯,以便我们使用EXPLAIN等相关工具来优化相应的SQL。
log-slow-queries = /var/log/slow_query.log
long_query_time = 5
#log-queries-not-using-indexes
MySQL的EXPLAIN命令是一个很好的工具,它能帮助我们查找query在执行查询过程中的一些细节。我们需要查看的一个重要点就是,扫描的行数,它会告诉你什么时候需要,在合适的字段中建立索引。
我们看一下下面这段SQL查询,我们可以通过给其中有3个字段加上索引来减少查询时间。
具体的操作,使用ALTER TABLE指令来操作。
...
FROM node node
WHERE node.STATUS = 1
AND node.TYPE IN ('story')
ORDER BY node.created DESC
‘status’, ‘type’ 和 ‘created’ 可以加上索引,如下:
mysql> ALTER TABLE node ADD INDEX (status, type, created);
锁表是数据库级别的另一个令人头疼的性能问题。默认情况下,Drupal的MySQL表使用的是MyISAM引擎。由于MyISAM在执行一个数据库操作时会锁住整个表,因此访问量大的网站经常出现数据库down掉的情况。如果你希望解决这个问题并试图寻求解决方案,InnoDB是一个比较好的解决办法。InnoDB是行级别的锁定而非表级别。在迁移到InnoDB的时候,注意数据库表的字段中是否有 auto_increment 的字段,因为这会导致在插入(INSERT)数据的时候性能会非常低,因为这是InnoDB也会锁住整个表以免出现重复的主键。
PHP
使用静态变量缓存是一个快速简单的缓存方式。这里有一个简单的示例。
function taxonomy_get_term($tid) {
return db_fetch_object(db_query('SELECT * FROM {term_data} WHERE tid = %d', $tid));
}
当页面加载的时候,这个函数可能被调用好多次,如果加上一个简单的静态变量缓存,那么就可以避免多次查询数据库,从而提高网站的性能。如下:
function taxonomy_get_term($tid) {
static $terms = array();
if (!isset($terms[$tid])) {
$terms[$tid] = db_fetch_object(
db_query('SELECT * from {term_data} WHERE tid = %d', $tid));
}
return $terms[$tid];
}
应用层-Drupal
Drupal是一个内容管理框架,Lullabot用它来作为大型站点的基础框架,Drupal是用PHP开发的,并且有相当多的第三方模块可以免费使用和扩展。它被比作是LEGOs就是因为它有很多的模块可以使用,你可以做很多代码检查,然后决定到底用那个模块到你的平台里面。如果一个模块能满足你的需求,你应该检查它是否使用了静态变量缓存、SQL是否被优化,还有代码是否符合标准。
通常的Drupal会有一些第三方的patch,这是因为模块在某些方面存在bug或者功能行缺陷,这些问题被报告在模块的问题列表里面(issue),你可以在该issue的页面找到这个patch。性能优化的基本要点是优化SQL查询,并且不要让数据库查询的同一个SQL语句在一次页面加载中运行多次。Devel模块是一个很好的调试工具,它可以帮你统计页面加载时间、内存使用以及页面的加载时间。
抛开我们的LAMP架构,缓存技术、硬件架构都是一些通用的网站开发最佳实践,但是在Drupal开发中,我们不仅需要减少在不同服务器的负载等待,并且还需要能很容易的管理数据以及代码的版本变化,(译者注:在Drupal中,很多设置是存在于数据库中的)。首先,最重要的是需要一个“可导出”的功能,这样数据就会变成可读的代码而不是数据库,并且在部署到不同的服务器后可以重用,而不需要重新设置。
“可导出”的概念来自于 Views模块,Eari Miles,他希望能找到一个方法来帮助开发人员调试他们遇到的问题,所以他开发了一个可导出的功能能让开发人员导出他们的Views到code文件,然后导入到本地的环境调试。这不仅仅给Views的开发者带来一个优秀的特性,而是让整个Drupal的思路变成了把数据库的设置可以变成结构化的文件,从而提高了性能。“可导出”的概念后来被Ctools和Panels模块的开发者借鉴并增强,其他的开发者也开始在各自的模块中实现这种”可导出“功能,目前已有相当多的模块已经实现了Ctools的 “可导出”功能。
最终,我们有了Features模块,它提供了一个界面可以选择和管理各种各样的“可导出”功能模块,它可以把Drupal的很多功能导出成一个自定义的”feature“模块,并且这个模块是可以被共享和重用的,当然我们不仅仅是为了共享和重用这些模块,更重要的是“Feature”已经变成了Drupal新建和部署流程中一个重要的工作流。
还有一个工具也已经渐渐成熟,并且成为任何一个Drupal专家的必备工具,那就是Drush。 Drush的意思是Drupal Shell, 是一种通过命令行控制Drupal站点的一个途径。他不仅提供了强大的命令快速操控你的站点,其他第三方模块也提供了对Drush的集成,创建他们自己模块相关的命令。
比如:Features模块提供了一些Drush命令,比如 list、update、revert 来操作features。此外 Backup and Migrate 模块提供了一个简单的创建SQL备份的命令。还有其他的一些模块也提供了相关的命令来操作Drupal和Git。 当然Drush不是唯一可以让你快速管理Drupal的方法,但是它避免了你通过网页经Apache服务来管理Drupal的繁琐步骤。
可以肯定的是,没有任何一个专业网站可以脱离版本控制,Lullabot过去用CVS, SVN,最近开始向Git过渡,但是不管你用什么,有一个你工作的备份,并且为工作在相同项目的团队保留版本是非常重要的。版本控制的优点很多,一个高性能的网站通常需要很多人在一起工作,所以版本控制是必须要有的。